This post is a detailed discussion into user profiles, their directories, and how they are—to put it bluntly—in total disarray on Windows and Linux (I haven’t used a Mac in ages, but I assume the situation is very similar there, too). Applications treat the user profile as a dumping ground, and any user with a reasonably wide list of installed software will find their user profile very difficult to traverse after some time in use. There are platform conventions and attempts to standardise things on more open-source platforms, but a lot of developers resolutely refuse to change the behaviour of their software for a variety of reasons (some less valid than others).
The first part is a deep dive into user profiles on Linux and Windows, and the conventions that have been established on these platforms over the years. The second section details how they are broken on each platform, and why they are broken.
This happens to be one of my “pet peeves” as well. One the left, my home directory. On the right, my home directory but with all the garbage unhidden. This is bananas.
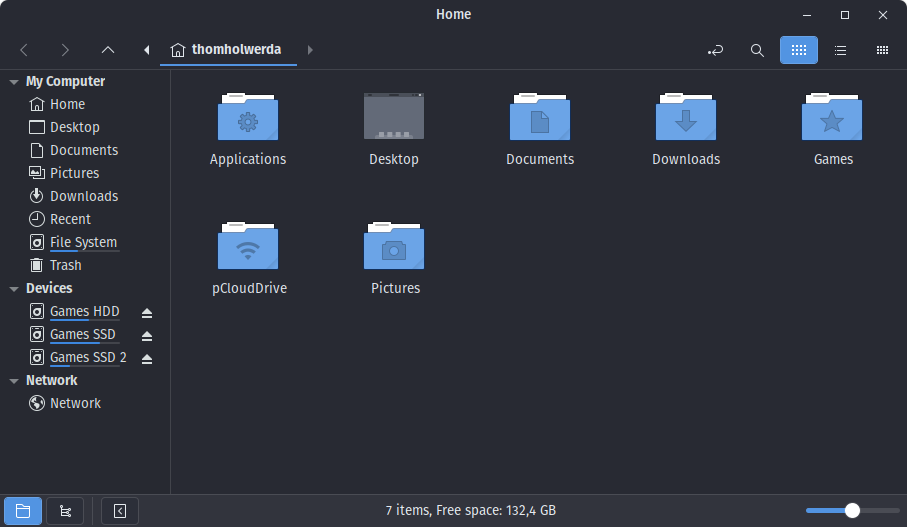
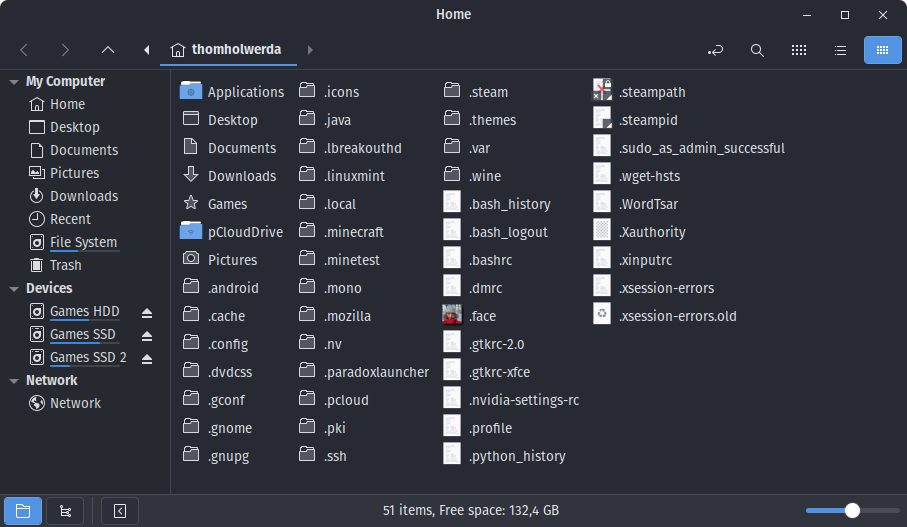
First, it’s been my long-standing conviction that if you, as a developer, need to actively hide things from the user in this way, you’re doing it wrong and and you’re writing bad code. If you’re an operating system developer, don’t use hidden directories and files to hide stuff from the user – use clear directory names, encourage the use of human-readable file names and contents, and put them in places that make sense.
Second, if you’re an application developer, follow the damn guidelines of the operating system you’re coding for. More often than not, these guidelines aren’t that hard to understand, they’re not onerous, and they’re certainly not going to be worse than whatever nonsense you yourself can come up with. Having a hidden .paradoxlauncher directory in my home directory displays just such an utter disrespect for me as a user, and tells me that you just don’t care, whether that’s you, the developer, personally, or whatever manager is instructing you to do the wrong thing.
At the same time, aside from excessive symlinking, there’s really no solution to any of this. As users, we just have to deal with the results of incompetence and ridiculous crunch culture in software and game development.
Thom Holwerda,
I agree with you it’s an awful mess. Both windows and linux are. I tried to fix this in my distro but it quickly became an insurmountable maintenance burden every time I wanted to install new software. So I gave up on it. Gobo linux had a similar idea and they got further than I did. It really is so much better when the file system hierarchy employs the “keep it simple, stupid” philosophy.
Anyway, one way to force a degree compliance in the wild software landscape might be to give every application it’s own VM/namespace such that it maters less where software tries to put things since it will exist in a self contained namespace. The real location can be easily managed. And shared paths can be mapped into them as needed so that from the user perspective their documents show up correctly.
Reminds me of how Windows handled global software installs when Terminal Services became integrated – file and registry virtualization for apps and silently and transparently redirecting read/write for some folders into virtual per-user versions of those folders as an overlay to the real location. UAC came along and leveraged that stuff too. Microsoft could certainly ensure Windows has writes into the root of %USERPROFILE% redirect to something like %APPDATA%\VirtualHome\[Appname] or something. I’m not sure off the top of my head how you’d do that on Linux but something similar is undoubtedly possible I’m sure.
That’s what Flatpak does. Snaps probably too. The application sees a temporary filesystem with $HOME set to what, to the host OS, is $HOME/.var/app/
(The user doesn’t see anything different if they’re using QFileDialog, GtkFileChooserNative or GFileDialog because GTK 3 and up and Qt 5 and up detect when XDG Portals are available and automatically redirect common dialogs through them. Applications using other toolkits can call the portal D-Bus APIs directly. Otherwise, manifest permissions can be used to make exceptions to the “temporary filesystem in a sandbox” model where parts of the host filesystem get mounted into it.)
The problem is retaining compatibility with cases like “MakeHuman interoperates with its Blender integration plugin by passing paths to assets, as it sees them, through IPC”… something that doesn’t work when the two apps are in different containers. Flatpak is a new app packaging model that apps are incrementally migrating to and new APIs are still being designed to meet the more edge-case needs. I think Microsoft is trying something similar with MSIX.
I still need to find time to go through and clear out all the stale stuff, but, for me, sandboxing and/or containerization has been the solution, since it works equally well for bad ports of Windows games like The Escapists that put non-hidden files into
~and then use something likegetpwnamorgetpwuidso I can’t use a wrapper which lies about theHOMEenvironment variable to relocate things.Flatpak where available, Firejail where I have to do it myself.
Linux/Unix developers are the absolute worst on this, they will drop directories starting with a dot in your Windows home directory and will not even flag those files as hidden, because it’s apparently Windows’ fault that Linux/Unix doesn’t have something resembling the AppData directory and doesn’t even have a real way to flag files as hidden (which means those Linux/Unix developers expect every other OS to hide files and folders starting with a dot despite this not making sense outside Linux/Unix environments for… reasons).
kurkosdr,
We haven’t always seen eye to eye on linux, but I think there’s a chance we might here, haha. I’ve gotten more accustomed to the system hierarchy, but I’ve never loved it. I actually hate the way an install scrambles files all over the place and how applications are installed differently depending on the installation method. The installation method shouldn’t matter, the end result should be the same! It’s a garbage pit. Yes, all these locations have a “purpose”, but I strongly feel that operating systems should be designed and organized to accommodate human needs and sensibilities. Instead the FHS standard forces humans to accommodate the operating system, which is backwards to how things should be IMHO.
https://en.wikipedia.org/wiki/Filesystem_Hierarchy_Standard
Alfman people get this wrong the idea that it was not built for humans. FHS issue is that it core design is old. Remember FHS starts in 1994 before we had containers and when harddrives and ram in systems was a lot smaller and cpu got a lot more powerful.
Doing something like flatpak on a 1994 system you would find yourself having horrible long application startup times. Apple in 2000 tried the dmg single file application install and due to CPU being too small got done in by the overhead and returned to using installers.
There is the problem of no such thing as common sense problem with human needs and sensibilities. Humans designed FHS for what matched their needs and sensibilities. Turns out does not match everyones.
Lot of these problems are attempted to be addressed by the lots Immutable Linux distributions but those also create their own share of problems.
Think endlessos where basically every application is a flatpak install resulting in very clean home directory that has a clean command that works. Then users run into problem not as many applications are installable.
The big thing as you found Alfman if you want applications to behave and upstream does not want to cooperate only option is containers because maintaining patches for all the upstream applications that will not cooperate is too much overhead.
oiaohm,
I disagree with your premise that computing limitations or startup times precluded better organization. By the 80s self contained applications worked and I cite DOS and early versions of windows as proven examples. No FHS mess there and self contained application directories worked fine. Everything a game or application needed could (and usually did) resided in a directory and it was objectively trivial to manage, so much easier than today on my FHS desktop.
Surely we can come up with something that vast majority of users would consider more organized than FHS.
You’re not wrong, not everyone has the same needs, but even so FHS is still a garbage dump and it’s really hard to make the case FHS was ever a good organization for humans. Seriously throwing all binaries and libraries system-wide into shared directories seems like something a very inexperienced user would do …
“Oh here’s a new application, let me throw all the binaries in with the rest of my binaries. Oh here’s another application, into the binaries directory they go…”
Yes, in practice any new standard doesn’t just have to be good on it’s own merits, but it has to play well with old standards otherwise things can start to break or otherwise create friction. This creates a conundrum whereby an otherwise appealing new standard might be frowned on because the industry has already settled on old standards. I’m sure you realize this applies to a lot of things in our world, from computers, the internet, the electric grid, cars, to airplanes and even rockets.
Take the 737 max, the engines are sub-optimally placed in terms of center of gravity such that when the engine accelerates, the aircrafts wants to pitch up and visa versa. This is subpar from an engineering standpoint. More fuel is wasted and the poor flying characteristics need to be compensated through software to mask the effects from the piots. So why did they do it this way? Well they could have engineered it to not have these flaws in the first place, but the 737 airframe already existed, was already certified, already had production lines, etc. Clearly boeing engineers could have done better, but they were doing their jobs within preexisting standards that defined the parameters for new innovation.
It’s a bit O/T but I hope you appreciate where I’m going from.
Yes, I can be a cheerleader for new cleaner standards, but at the same time, I know that realistically the old standards are going to stick around for a long time and whatever we propose has to deal with this fact. Unfortunately for devs like me, unless there is significant industry buy in, the value of a new standard would be completely lost if only a handful of applications use it while tens of thousands do not. I have to concede this is a challenge, and perhaps even an insurmountable one.
“I disagree with your premise that computing limitations or startup times precluded better organization. By the 80s self contained applications worked and I cite DOS and early versions of windows as proven examples. No FHS mess there and self contained application directories worked fine. ”
Dos did have it limitations of only a single application at a time. Windows 1.0 had configuration and dll hell because configurations and dlls were all dumped in one directory no sorting at all so no these were not self contained applications. Yes as soon as you attempt to do multi applications and save disc space things started going horrible wrong. Unix, Windows, Mac OS…
FHS is for multi applications sharing resources and sharing disc space.
FHS /etc directory so users wanting to find configuration files could go to one directory. bin directories there you executrices to run…
The layout makes sense for a particular workflow.
“Seriously throwing all binaries and libraries system-wide into shared directories seems like something a very inexperienced user would do …”
FHS was designed in feb 1994 guess when we start seeing RPM and DKPG as in package managers in number Jan 1994. FHS was always designed to be used in combination with package management. Package managers have lists of what they installed issue is they don’t track what is created after very well. Yes 1994 we did not have the tech to track what was created after.
“Surely we can come up with something that vast majority of users would consider more organized than FHS.”
Its not that simple. Make it contained to know what application installed what backing up all configurations files in one simple hit comes harder. This is one of the downsides you notice with the flatpak solution if you are just attempting to backup configuration without extras flatpak /.var/app is harder.
–Yes, I can be a cheerleader for new cleaner standards,–
Microsoft, FHS, Apple… many different parties have done their own attempt at cleaner standards for this. Lets take the old standard for one min and check something do applications developers follow the old standards dependably the answer is no they do not.
Yes the old unix standard that all configurations files in home directory will start with a . guess what there are applications on Linux that use no dot configurations files. Then you have newer XDG standard for the home directory and you find applications no doing those correctly.
Failure to learn from history doomed to repeat it. One solid rule for new standard is application developers cannot be trusted todo the right thing. You have people saying it here a Unix/Mac/Linux application ported to windows will have habit of still doing Unix/Linux things. Windows applicaiton ported to Linux/mac will have the habit of doing the same thing the other way. Developers will disobey standards. Developers will not update to newer versions of standards as well without major road blocks.
FHS has it reasons something they did not consider as problems that they should of.
Sorted the way FHS is make sense of backing up configuration files without all the binaries, having simple locations to search for documentation on how to use programs because all documentation is limited number of directory and so on. Yes like it or not there are reasons to the FHS design. There are workflow advantages to the FHS design. There are downside for keeping system clean without package management and containerization to be able track what owns to what application.
But it does not matter if it the Mac OS, the Linux the Windows… standards for how applications should place their files into the system or home directory the one thing you can be sure to have is on any platform is applications disobeying the rules if they can.
oiaohm,
While that’s true for MS-DOS, others did support multitasking. Regardless, I’m baffled as to why you’d even bring it up in this discussion. as the addition of multitasking has no bearing on the installation locations of application files.
Not totally true, many applications did not do that because they didn’t share resources between applications. DLLs did work when they were distributed and installed alongside the application. I don’t contest that it did become a DLL hell, but the shared system directory was not a technical requirement. IMHO, much like the /lib directory on linux, the system directory on windows was not engineered well and both evolved into DLL hell.
It was a poor layout for humans when it was invented and it’s a garbage layout when we try and scale it up today. We keep it this way because it’s the standard. You’re welcome to disagree with me but I say it’s hot garbage and you’ll not convince me otherwise. It is practically impossible for the masses to manage it without front end tools to cover the underlying mess, and even then it still seeps through the cracks.
I can’t think of a single case where someone would actually want heaps of binaries and libraries as LHS has it (other than being the legacy standard of course). Say on windows we find all the binaries and move them into a /bin directory. How do you sell that as a feature? Who does this benefit?? Certainly not human users. Maybe a global bin directory was manageable at the dawn of computing when there weren’t that many applications. But It’s insanity to suggest that it’s a good organization today.
I think there are much better solutions, but we clearly we took this path instead and so here we are having to deal with it. In many ways we’d have to backtrack in order to get into better territory. Flatpak doesn’t fix everything and it has some pain points. Even then I’d say they don’t go far enough in terms of reaching a more ideal foundation. But I can’t critisize them too much because I’m very aware of how difficult it is to fix the problems while remaining compatible with that which is already in place.
I agree. It’s like I said with the airplane example, we’re often constrained by the standards that already exist because everybody’s already on board with them, for better or worse.
There are much better ways to achieve those goals without requiring all files of a type to go into a big unmanageable garbage heap.
This is a damning downside for FHS. I especially hate the way applications end up hard coding FHS paths at build time. The same application may have to get built using different constants depending on where it is being installed in a particular distro. That’s just ridiculous. Or just as bad some linux applications end up scanning a dozen of directories for files because they have no idea where they’ll actually be installed. This is inefficient and creates tons of problems, most of which go away when you keep application files together, which is the opposite of what FHS does.
Yes I agree, but if the rules didn’t suck and directories were well organized, I think more developers would actually appreciate it. I certainly would.
“as the addition of multitasking has no bearing on the installation locations of application files.”
It does have a bearing. Particularly in combination with low ram and low cpu power.
“I can’t think of a single case where someone would actually want heaps of binaries and libraries as LHS has it (other than being the legacy standard of course). Say on windows we find all the binaries and move them into a /bin directory. How do you sell that as a feature? ”
This not being able to take the mind set of limited resources of 1994 or current day embedded limited resources. Windows being a graphical OS it does not make sense to shove everything into /bin. Where does it make sense command line OS. 1994 Linux/Unix where LHS comes from default is command line. So you are placing your executable binary in the bin directory and a file is already there of the same name this is going to be trouble for command line operation because as user have a overlap.
Libraries in the same directory makes it simple to find duplication in functionality that results in extra ram usage.
This particular workflow where you are a command line os doing multi tasking with limited memory and cpu the LHS design starts making major sense. 1994 parties developing LHS was still more command-line than graphical.
Current graphical desktop with increase ram, cpu and storage the LHS design to make optimization for low ram. cpu, storage and command line use does not make sense. This is a warning that we can take away from LHS is a design that looks good today in 5 years could start looking like a problem child then another 5 years start looking really stupid then another 5 years be really horrible as the workflows of users change.
“This is a damning downside for FHS. I especially hate the way applications end up hard coding FHS paths at build time. The same application may have to get built using different constants depending on where it is being installed in a particular distro. That’s just ridiculous. ”
Bad new here to take note I wrote about before about developers ignoring existing standards. Most of what you proceed to write is developers doing the wrong thing.
ELF from SUN and AT&T include RPATH and /proc features that mean hard coding FHS path is not required and the mess you just talked about should not be happening but hey developers will do the wrong thing. Yes the ELF/proc standard Linux is based correctly developed applications should not have this problem. Yes SUN and AT&T develop the ELF format and match /proc features to locate application install location for System V Release 4.0 in 1988 so before the first Line of linux source code and System V Release 4.0 documentation on that Linus starts with when he writes starts writing Linux kernel.
https://stackoverflow.com/questions/933850/how-do-i-find-the-location-of-the-executable-in-c
“On Unixes with /proc really straight and realiable way is to:
readlink(“/proc/self/exe”, buf, bufsize) (Linux)
readlink(“/proc/curproc/file”, buf, bufsize) (FreeBSD)
readlink(“/proc/self/path/a.out”, buf, bufsize) (Solaris)
On Unixes without /proc (i.e. if above fails):
If argv[0] starts with “/” (absolute path) this is the path.
Otherwise if argv[0] contains “/” (relative path) append it to cwd (assuming it hasn’t been changed yet).
Otherwise search directories in $PATH for executable argv[0].
Afterwards it may be reasonable to check whether the executable isn’t actually a symlink. If it is resolve it relative to the symlink directory.
This step is not necessary in /proc method (at least for Linux). There the proc symlink points directly to executable.”
Yes Unix without /proc into weeds and its that into weeds method that you find developers using on /proc supporting Unix/Linux/BSD systems.
You are on Linux/BSD/Solaris based OS its check exactly 1 file to find out exactly where application was installed but posix standard did not go and give this file a universal same name bugger us.
“Or just as bad some linux applications end up scanning a dozen of directories for files because they have no idea where they’ll actually be installed.”
This is using a generic Unix proc less solution everywhere so a developer mistake if this is files the application itself installed. Now looking for applications installed by other programs install location could need userfeed back on where they are.
There is one major problem that is truly hard coded. That the dynamic binary loader of elf.
Yes little note LHS had you installing applications in / /usr and /usr/local in the first draft version and you were by LHS meant to be able to place you applicaition in any one of those 3 locations. The reality is hard coded path to install location is in breach of LHS original guidelines that were released next to the standard. I really do wish those had been written into the LHS standard both Unix without /proc complained too much. Yes being compatible with legacy has downsides.
oiaohm,
Sorry, but you were conflating multitasking with file locations, and now you are conflating a GUI OS with file locations. I’m not trying to be difficult, but it’s simply untrue that it makes more sense to clobber binaries together depending on the application interface or multitasking support. An unorganized mess is still a mess regardless of what the application is doing.
This too is false. Location on the file system, like residing in a single directory or not, has no bearing on whether it can use shared ram. You absolutely can organize libraries within the file system. The OS just needs to support it.
No, you keep going back to this but the entire premise is very flawed. At the beginning it might have been easier to implement a system where everything gets thrown into the same directory, but from an organizational perspective the bin dumping grounds is badly organized for humans. DOS proves high level organization was technically feasible on early hardware, but *nix stuck with their initial conventions. Perhaps their attitude was “don’t fix what ain’t broke”, but the result was a mess that got worse with time as the number of applications ballooned. The only situation I can think of back then where a lack of organization might be justified is when floppy disks were naturally providing a degree of physical organization in lieu of operating system organization. In other words, I wouldn’t need the OS to keep applications organized when the disk is physically doing it already.
Again, this is conflating completely separate topics. From both the technical and user organization standpoint, one has no bearing on the other. The notion that proper application directories is somehow a byproduct of GUI/text environment doesn’t really hold water. Instead it’s more a byproduct of OS lineage.
Edit: anyway, regardless of how you want to justify those decisions in the past, it seems that at least we agree that it could use more organization today.
“This too is false. Location on the file system, like residing in a single directory or not, has no bearing on whether it can use shared ram. You absolutely can organize libraries within the file system. The OS just needs to support it.”
This is the mistake. FHS and the prior Unix layout is good for human attempting to make system optimized on memory usage. So a party doing embedded system with limited ram it still make sense.
Directory listing everything in one folder only that directory list in memory for look ups. Spread over directories does result in higher memory usage. Dos this was not a problem it not multi tasking.
Same problem with hard coding install location that makes binary that uses slightly less memory.
FHS design comes from a history Need. If you have a case that still has that Need its not a bad solution. Remember FHS with Package manager of some for is the history solution. Package manager is not general running thing.
“You’re not wrong, not everyone has the same needs, but even so FHS is still a garbage dump and it’s really hard to make the case FHS was ever a good organization for humans.”
What you wrote here is critical. Not everyone has the same needs and those difference in needs has had effects on what has been implemented. FHS was design for the needs of 1994 and before. Multi tasking, command line with limited ram and limited cpu. This results in FHS choices that make sense to achieve to make it simple for human to achieve goal that have other adverse effects on achieving any other goal.
Like it or not there is a memory saving by using FHS over using something like NixOS yes not all Linux distributions follow the FHS standard. NixOS has applications all installed in their own folders like dos and it does result in higher memory usage than FHS. NixOS also allows multi incompatible dependencies to be installed. NixOS layout was not designed for low memory systems.
https://nixos.org/guides/how-nix-works
I would not say that nix paths are the most user friendly. When using nixos it is a very different beast. Conflicting commands for command line usage in nixos leads to a set of horrible work around. Nix did not attempt to fix the home directory problem.
This is the problem with what you are saying Alfman parties have done different install systems on Linux that don’t use FHS. I don’t have to guess what the advantages of FHS is because I have compared the alternatives to FHS to see the result.
FHS has design made to be helpful for humans to make an install suited to low ram, low cpu, low storage solution that is command line. For a general desktop user who just wants their application to work and to cleanly install and uninstall this does not match up.
Its the old saying you cannot have your cake and eat. The price of a nicer layout for desktop users Alfman is higher ram usage and will result in more disc usage. Yes everything people complain about with flatpak and snap..
This is the catch here for what FHS is designed for its good to see duplicate dlls with restrictions to single command due to sticking resources of the same type in single directories . Problem is that not what desktop users really need.
The problem is the normal rose color glasses problem. Its really simple to say humans of the past were stupid to do X without in fact attempting to work to the limitations of the past and notice the way that looks stupid turns out to be effective with the limitations of back then and the more modern method(that the could have done) is too resource costly.
FHS has it reasons. Items like NixOS allow you to see them. Of course with todays system the few meg of memory of extra cost something like NixOS cost today is bugger all today but then think 1994 with 16 megs of memory 1 meg of extra cost is absolutely nightmare. People doing embedded systems in embeded controllers still at times have 1 to 16 meg memory limits at times so there are still places with FHS today makes sense.
Alfman please note I am not saying FHS suits the use case you were trying to do. But you keep on saying its hard to write a use case for FHS. This is more you have not spent to time with items like NixOS and the like in a resource restricted(as in cpu/mem) to have the cost clearly show itself.
FHS design is about having a layout to help human achieve lowest memory usage and low storage usage and be commandline os and be multi tasking with the issue FHS goes all in on these objectives at the cost of basically everything else.
FHS is clear warning sign remember you said everyone needs are not the same then has not taken this in. When you say you cannot write up a good case for FHS usage means you cannot see the needs that made it.
Then there are things you miss take deb packages. Early debian package install include relocatable installation. If packages are built correctly(sorry to say 90% of debian is not) you should be able to install application using dpkg where ever you like in the / direct in the /usr in the /usr/locol in per application path in users home directory. Path of least effort and lowest memory usage equals don’t support relocatable location. Remember relocatable binaries was a feature Sun and At&T added in 1988 before Linux existed.
Yes FHS under /opt directory support installing applications in their own individual paths this was added to FHS. So that /usr could be core OS and add on applications by users could be in the /opt folder with their own libraries. FHS does support cleaner layouts.
Something else to remember Linux does not have file extensions as required. bin directory in FHS come from Unix world as a simple way to see that something is executable. this is why FHS opt is /opt/application name/bin/executable.
The FHS makes more sense when you recognize that UNIX is a C IDE masquerading as an operating system and Linux inherited that. (Case in point, `man` comingling OS documentation, libc documentation, and platform library documentation at the same level.)
The design originated with prioritizing having standard search paths for .so, .a, and .h files (which got weakened when we started having enough of them to start needing subfolders and pkg-config) and for the “function calls” (executable binaries) used by shell scripts in the days when inittab was good enough for init because you had maybe three or four background processes on entire system.
It’s basically the filesystem equivalent to how .h files exist to make C compilation work on the underpowered machine it was developed on.
TL;DR: FHS is the most visible remaining artifact of POSIX being the big boy version of “Commodore BASIC is the operating system”. Its design originated in the days before emacs even existed to be the previous recipient of “Electron/node-webkit is a bloated pile of garbage” hate and FHS itself was codified in the days when Windows NT was unviable for most people because the 12MB of RAM minimum requirement cost a fortune.
(I got to enjoy Windows 95 on my father’s work laptops, but our home 386 certainly wasn’t going to be upgraded to it. It was running Windows 3.1 on 2MiB of RAM and Windows 95 required 4MiB.)
By the time the Filesystem Hierarchy Standard was published in the mid 90s, computers had no problem handling directory resources.
You are very much conflating things.
There were multitasking operating systems that used application directories as well as single tasking operating systems that used application directories. Every sign points to *nix continuing its /bin lineage despite operating systems of all types being perfectly capable of handling nested directories! This is not altogether surprising, many users hate change so it stuck even though it was poorly organized.
I am not going to agree with you that FHS was a technical necessity, it really wasn’t. Given all the counter examples that existed, I’m surprised you are trying to defend such a position.
We’ll have to agree to disagree.
ssokolow you close you covered the home user. Back in 1994 you might have had a system using FHS or unix prior with 256 megs of memory one problem you have 200 users logged into that poor system over thin text base terminals. I do know that first hand because my first access to Unix was 1995 at a university on a shared server with 300+ active users and only 256 megs of ram.
Yes home computers did not have much ram and mainframes and servers from the time FHS started was packing users in like sardines in tins to make the most out of the expensive ram and cpus. Yes of course when users are packed in on a server like sardines in tins command line/text based interfaces only because starting up graphical application is going to take too much ram.
FHS is designed for stuffing as many users as possible in the least amount of ram used.
Low memory, low cpu, with Multi tasking and Multi user puts some very strict restrictions on design and those show though in FHS. Yes FHS is still good in cases were you have the same problem today like routers.
You can think of the FHS as the software equal to train services having “Passenger pusher” to get everyone in the train. Users are not exactly happy but it designed to get the most number of users/people in the limited amount of space and both do that job well.
ssokolow (Hey, OSNews U2F/WebAuthn is broken on Firefox!),
You make some very good points. There’s a reason those files are located there. I still think that *ideally* all of an application’s resources (ie documentation/binaries/include files/etc) are best organized together. So instead of moving files around to satisfy OS search, the operating system should have robust and optimized indexing facilities.
When I think of file system problems, I often compare them to database problems that we’ve solved already using elegant primitives that are highly optimized, much more so than the file system ever will be. I wish file systems would borrow some of the innovation we’ve had in the database world such as transactions, indexes, materialized views, constraints, foreign keys, and so on.
Say these things had been designed into linux early on, the software and distros we use today would be able to take it for granted today. For example, resources wouldn’t have to be moved out of their respective application directories. They’d stay with the application where they belong and would be accessible through a very fast index lookup using fewer syscalls and less disk IO than is currently needed.
I learned on my parent’s computer too. I think they started with a 486, but I didn’t do very much computering until we bought a P2.
oiaohm,
Memory consumption obviously increases with the number of users, but much less so where shared application files resides in a directory tree. You could have hundreds of users, but when they’re all using the same applications that’s actually quite efficient.
Even low memory devices were handling directories fine in the 90s. And typical routers don’t even have many binaries anyways. Can we agree to disagree?
“Memory consumption obviously increases with the number of users, but much less so where shared application files resides in a directory tree. You could have hundreds of users, but when they’re all using the same applications that’s actually quite efficient.”
You need to be thinking more about it. All the libraries in one directory lets say someone running nano and something else is running bash. They still have shared because there is a single glibc. FHS layout makes sense for spotting memory usage error of having like different libraries for the same thing. Or duplicate commands for the same thing. Remember what you said when they are using the same applications you can expand this to same applications and same libraries. What kind of layout suits optimizing the system so many users will all find the same application to perform the same task and optimizing when users are not performing the same task have the most shared possible. For what FHS layout is designed todo its good.
“Even low memory devices were handling directories fine in the 90s. And typical routers don’t even have many binaries anyways. ”
This miss that routers and other low memory devices were using FHS and unix prior format in the 90s and that was not just for unix compatibility.
Routers don’t have many binaries that true. But you can still have 50 to 100 active processes even in a 1980-1990s router. If those processes are not effective on sharing memory because don’t have effect use of shared libraries you can find yourself out of memory very quickly when you are playing with 1 to 2 megs of ram. By the early 90s people had moved out of routers with static binary executable because memory issue with the functionality had come a problem and this got worse with the introduction of ssh and http instead of the old school telnet.
This is the problem with FHS breaking application install up into pieces the way FHS is doing it is to make it simple workflow as a person setting up server with what is practically too many users or a router with basically very bare bones resources to spot the cases where you are going to be using too much memory. Like you go into /lib and there are like to libc you straight know this is going to be excess memory usage.
All the manuals/man pages being in the one folder you are out of disc space you can delete the manuals to recover space on a router for another example of means to apply space optimizing axe.
Alfman I would not say agree to disagree. You just need to look at FHS from the point of view that you are working with really limited resources. What looks like mistakes about FHS happens to be what happens when you make a layout suited to optimizing into a memory/cpu constrained system.
Please note I do agree with you Alfman for today desktop usage where we have more storage and more ram that we can afford not be as cpu/memory effective to have something more intuitive. But the time FHS came from with Linux and Unix being used in mainframes/server/routers and almost all those cases at the time not really have enough ram or cpu for what they were attempting todo. This means being efficient only when all users run the same application does not cut it.
Remember you said FHS does not have a use case. FHS is still useful today if your use case is we have a system under resources and you need to optimize the install that it can work. FHS layout is designed to make it simple to find areas remove to reduce over all resource usage.
FHS being designed help to get as close as possible to the most optimize for resource usage end up being for desktop users like trying to stuff a human in a set of clothes for the 100 percent perfectly average human. Yes a set of clothes designed for the absolutely average human fits no human on the planet. Also like using a hammer to drive in a screw yes that works but badly. But in the 1990s the resource problem was quite a large problem.
Scary point the 650kb of xt dos pc was on adverage three the amount of ram per user that average mainframe user had at the time. This is why I said stuffed in sardine can. You can think of a dos/early windows PC as a sardine that has the complete sardine can to itself. Routers and servers of that time you have a can that should hold 6 sardines but someone has managed to stuff 12 in. FHS is designed around pulling off stupid levels of over allocations including chopping off bits less important bits of applications to pull it off..
oiaohm,
I’ve thought plenty about it and you haven’t convinced me. Memory consumption isn’t significantly impacted by what directory a file is in.
Again your totally conflating separate things. That fact that you have files in a different location doesn’t mean you can’t use the same shared memory optimizations. The only difference is where the loader finds the file. Once a shared file is loaded into memory it doesn’t really matter where it was, the applications and memory subsystem don’t care about that.
Why in the world do you assume that a non-FHS file system layout would not use shared memory? If that’s really what you are thinking a non-FHS file system would do, then you’ve got the wrong idea. Nobody was suggesting shared memory wouldn’t be used, certainly not me.
If you assume shared memory were eliminated, sure memory consumption would explode, but that’s not an apples to apples comparison and the assumption itself is totally flawed. So please understand that when I say resources should be kept in an organized directory structure, we’re not talking about eliminating shared memory, merely keeping the files more organized doesn’t otherwise change how they’re handled by the memory subsystem.
“If you assume shared memory were eliminated, sure memory consumption would explode, but that’s not an apples to apples comparison and the assumption itself is totally flawed. So please understand that when I say resources should be kept in an organized directory structure, we’re not talking about eliminating shared memory, merely keeping the files more organized doesn’t otherwise change how they’re handled by the memory subsystem.”
Read what you highlighted carefully Alfman.
“effect use” is the key word here.
NixOS does not remove use of shared memory. But as you start putting files ordered by applications it comes harder to see when you have doubled up shared libraries or doubled up icon files or doubled up… Each of these double up without deplication processes on file systems results in extra memory usage. Processing cost of de-duplication on file system was not was not viable in 1994..
“Once a shared file is loaded into memory it doesn’t really matter where it was, the applications and memory subsystem don’t care about that.”
This is not in fact true on Linux, BSD and Unix systems where everything is a file.
Lets say I have a library x.so installed globally /usr/lib and a library x.so in the applications rpath that happens to be /opt/application/lib that are absolutely identical other than the path they are stored on the file system and the file system does not have de-duplication functionality what happens next. The library from /opt/application/lib loads into memory because the application in opt was run. Now you run a system installed application the that uses the the same library except it was installed in /usr/bin the result is the copy on /usr/lib was loaded in memory you now have double memory usage. Yes both programs are using shared libraries but due to the same library being stored in 2 different locations the result is twice the memory usage.
The reality memory system and the elf loader of Linux does in fact care were the file was and in fact memory system does in fact keep track of the location. Yes early FHS did not have opt only had / /usr and /usr/local as base paths..
Alfman I am not saying applications will not be using shared memory. The issue is effective usage of shared memory. FHS is designed that shoves all shared libraries in limited number of folders is to reduce the chances for the case of 2 or more copies of the same library to exist.
Thing to remember with the everything is a file model without file system de-duplication to make the file appear as one entry to the memory system even that it has different locations each duplication on the file system equals duplicating memory usage.. Please note this duplicating memory usage could be a icon, shared library …. basically any shared resource application or user could use.
Remember 1994 and before when FHS core design is from de-duplication file systems did not exist yet. Also de-duplication support on file systems have a overhead cost.
Please note linux KSM does not de-duplicate memory blocks that come from files loaded from disc that have different locations either.
So different layout Alfman to remain as memory effective as FHS gets you need to either extend KSM or have de-duplication file system.
Alfman you have had a key miss understanding. Under Linux, BSD, Unix systems and anything else that uses everything is a file as part of memory management the file path of where items is stored has direct effect on memory usage.
The way original FHS is to make it simpler to impossible to duplicate up .so libraries on the storage. Think about you go to but the same library a second time when installing a different application into /usr/lib you are going to end up 1 copy because the design results in you over writing the prior one. Same with shared font and so on. FHS design is about prevent duplication. Of course preventing duplication to keep memory usage low is what causes dependency hell.
This is the problem you cannot have absolutely ideal memory usage for low memory environments and not end up having to solve dependency hell problems.
Alfman under Linux and other everything as a file OS you should have noticed at least once you delete a file while some application has that file open that it does not delete from the storage until the application closes this is because the memory system has that location open. Location on disc and memory on everything as a file OSs is linked in many ways.
Also Alfman you must have also missed that when Linux and other everything as file OS run out of memory they will have released non changed memory of files that are on storage this is because there is a direct link between memory and file location. The memory system cares where a file is located.
Now this brings up another thing notice how you have /usr/lib /usr/bin…. Now think memory system of everything of a file OS design is going to be keeping these complete file locations in memory. You change the layout you make these longer you have straight up expanded memory usage. Yes routers and other really tight on memory devices normally don’t have the /usr bit because those 4 extra chars add up. FHS allows for installs without /usr.
Memory effective when having everything is a file OS is like it or not Alfman dependent on the file system locations of stuff. On modern desktop systems today we can afford to not be memory as effective as 1994 because we have more memory. Some embedded devices today still need to be as memory effective as possible and those areas FHS still fits well.
oiaohm,
We’re going round in circles. The fact of the matter is that shared memory works regardless of what directory a file is in!!! The shared memory subsystem doesn’t give a crap about directories. And this notion that developers of the 1990s would not have been able to implement organized software directories without FHS is just silly.
No oiaohm, I don’t know why you seem to be getting completely sidetracked, but please take a step back. From the start I was always just talking about organizing the files we have already…not duplicating (or de-duplicating) them. I’ve been trying to get us to agree on basic facts, like merely moving files into organized directories does not technically make shared memory any less effective. Technically it can be just as effective as under FHS.
Yes, linux uses those conventions, but the point here is they didn’t have to. FHS was a compatibility convention and THAT the was the primary value of FHS rather than a technical requirement.
Well traditionally the OS/distro is responsible for what name to give to files in /bin. But the onus to do this still applies regardless of FHS. Nothing precludes them from using an organized structure instead of dumping everything into a mosh pit. Just as a distro can/should check for collisions before packaging, they can/should check for dups before packaging. We’re not talking about rocket science here, it’s just different paths.
You seem to be fixated on solving today’s problems with flatpak like dedup, and that is fine. But then you are transposing that problem to 1994 FHS where your argument becomes disingenuous since we weren’t using flatpaks.
Technically dedup could have been useful in the case where several users installed the same software in their home directories, but the same benefit or lack thereof applies to both FHS and non-FHS!
What hardware existed in 1994 for a given market is irrelevant, because the broad strokes of FHS which are being complained about trace back to early UNIX on PDP-11 and the FHS people aren’t bold enough to try changing that.
FHS changes things like the split between /bin, /sbin, /usr/bin, /usr/sbin, /usr/local/bin, and /usr/local/sbin, not whether local applications should be split into $PREFIX/bin, $PREFIX/lib, $PREFIX/share, etc.
Apple used to do that for stuff that didn’t need to be installed into the system as part of classic Mac OS.
It’s nice for being able to easily try out and then remove stuff on the Power Mac G4 in my retro-hobby corner, but needing to remember how to force a regeneration of the database, or manually point to an application that it lost track of the file association for during a reorganization is annoying, so I can see why people would have unfavourable memories of the design.
Cache invalidation bugs are a plague on the industry even today and, when it does break, Linux’s .desktop entry system is particularly bad about making it difficult to figure out which (often DE-specific) cache to invalidate and how to do it without rebooting.
Both Windows Longhorn and GNOME 3 were envisioned to have database filesystems as selling points, but both backpedalled. Like 3D movies or Desktop-Mobile convergence, it’s something a lot of techies want, which keeps proving more difficult to implement than expected… In this case, due to stubborn performance problems.
In the end, it’s a primary key selection problem. In a hierarchical store, you have to bake one GROUP BY query into the filesystem… which one are you going to choose?
The approach UNIX took was based on the idea that queries like “Find me this binary to execute” or “Find me this library to link/load” or “Find me this manpage to display” or “Find me this header to #include” happen much more often than “Install/upgrade/remove this application” and modern package managers are essentially a hack to implement an alternative GROUP BY query at a higher level.
Personally, when I saw the screenshots of Nautilus visualizing a prototype GNOME database filesystem implementation years ago, I felt a sense of dread because I didn’t feel “advanced querying”, I felt “shifting sands”… like how Cathode Ray Dude describes Windows 3.1 as having no firmament in his video on Norton Desktop and Windows 95 as finally giving you “the desktop”… a place where you can “live in”… where it may be messy, but you can put things and they’ll stay there.
Like a mechanic working on an engine, you don’t want the engine to Transformers itself into whatever shape that makes it easiest to access any individual component, because that destroys your spatial reasoning ability. (A few transformations is fine… a separate transformation for every side of every component is not.)
Heck, the web is a giant database where you can’t use simple hierarchy, and, from the beginning, UX people like Jakob Nielsen have been harping on things like “Don’t break the Back button”, “Put your logo in the top left corner and link it to the site root” and “Publish a site map and put it in your site footer” in an effort to restore that sense of spatial reasoning.
As humans, we often struggle with things that lack an an intrinsic structure with an authoritative view that can be referred to in order to re-ground our perception of them. (i.e. As a species, we have a psychological need for there to be a standard “this way up” to hold our maps. Be it the old “toward the direction the sun sets” that gave us the verbs ‘orient’, ‘orientate’, and ‘re-orient’, toward Mecca like maps in the islamic world historically were designed for, or toward North, established in the days before we knew true north and magnetic north were different things and that both vary over time, the latter much more than the former since magnetic fields are less coupled to inertia.)
Remember when an entire program was always installed in “Program Files” on Windows? No? Me either. Because that was NEVER the situation, ever. Windows applications have always been installed “where-ever-the-fuck”. Nothing has changed, except some people seem to actually like that tornado of a folder called the AppData directory. And what is roaming? Folks are literally in this thread saying “just use AppData correctly.” ROFLMAO. Seriously?! That thing is the WORST! Have you ever tried to back that thing up? Or dive in an pair it down? What an absolutely nightmare! How can anyone think that’s a “good thing”™? Such a cruel joke!
Also, it’s Microsoft Windows. Why would the terrible design of that thing surprise anyone? They invented the registry (which is somehow still a thing) after all…
“Have you ever tried to back that thing up? Or dive in an pair it down?”
Yes, I’ve done that a few times. Never had an issue. I’m definitely not the target of this article. Its all a organizational mess, true but It does not impact me one iota on any operating system. Any file based config is better than the awfulness of the registry.
Bill Shooter of Bul,
The better question is if you’ve ever had a problem with restore 🙂
User data isn’t as bad, but when it comes to restoring applications themselves, that’s a treat, haha. Even if you have a full system backup including registry and system directories, restoring software onto a new system is such a pain if it has many dependencies…I’d rather just reinstall.
Speaking of awfulness, have you seen this?
https://rwmj.wordpress.com/2010/02/18/why-the-windows-registry-sucks-technically/
(It goes into detail on how, purely on the technical level and completely unrelated to how its used, the windows registry is hot garbage. Many of its points boil down to “Writing filesystems is hard and it’s even harder when someone with no filesystem development experience doesn’t realize that’s what they’re writing.”.)
EDIT: Huh. I guess I owe the security plugin OSNews is using an apology. I expected this post to be lost in the ether when I finished filling out the “we think you did something suspicious” form. (Though I guess that’s more a damnation of how bad the norm is for online IDS-esque tech.)
If your company’s IT department chose to provision machines using a Windows NT Domain Server, Roaming is the portion of AppData that gets sync’d to the server so it’s present and up-to-date no matter which client/terminal you log in on.
It’s literally “the stuff that should be backed up” by design and any applications which don’t use it that way are doing it wrong according to Microsoft’s own developer documentation.
Local is for stuff too big (eg. the browser cache, downloaded mods, etc.) or too machine-specific (eg. preferences tied to monitor resolution) to be sync’d to the server.
I just looked up LocalLow and it’s apparently some kind of “Local, but for applications running in a privelege-restricted context” thing.
If you want to be confused about something, read the XDG Base Directory Specification for Linux.
Sure, ~/.cache is like Local, but only a subset of it, and it’s hella confusing when to use ~/.config/ and when to use ~/.local/share if you’re just reading the spec.
(I finally had it explained to me that the intent was that ~/.config/ is machine-specific stuff that’d be annoying but not terrible to lose, such as remembered window geometry and toolbar configs, which are likely to vary based on your screen size, while `~/.local/share` is intended as “~/Documents, but for stuff the application manages instead of the user, like Thunderbird mailboxes or save slots in games”.)
Which completely destroys the whole roaming/backupable split because, without a Roaming/Local split, game devs look at it and see mods as being closer to userdata than to configuration or cache and put what could be gigabytes of mods in ~/.local/share/MyGameName/mods/ or whatever.
As for installing to AppData – I get the desire to isolate folders in Windows to the unprivileged location under the home directory. But why can’t we just have a simple folder structure. It’s 2023 and Windows still has 2 friggin Program Files directories in the root file system. That made sense when everything was a hack in the 1990s, but COME ON.
How about a simple c:\users\myname\apps directory in addition to the root version, without whatever the hell roaming, local, locallow is in it? Or even better, deprecate the old insecure by default organization, and finally just configure Windows to not suck? (Windows isn’t badly implemented, it’s just badly configured.) Why is everything so difficult in Windows land?
(I know the answer – it’s because once something is implemented in Windows, it NEVER changes, because that’s how proprietary commercial software is built. Only forward, and nothing can change. There’s NO incentive to EVER update or change anything, because that would cost MONEY. Windows doesn’t even have a dedicated dev team any more. So MS still supports 2 Program Files directories in the root of the drive, and it likely will until people stop using Windows. Seriously, why do people still use this pile of hot garbage…)
I assume it’s the same reason Linux has /lib32 and /lib64. So you can install both the 32-bit and 64-bit versions of the same dependency without conflict in the edge-cases where that concern actually applies to Program Files.
ssokolow (Hey, OSNews U2F/WebAuthn is broken on Firefox!),
The problem with the two program files directories is that it only solves a problem that microsoft themselves invented. No other operating system including earlier versions of windows have had to rely on multiple program files directories and virtual file system & registry remapping to support multiple architectures. I don’t think MS even did it on purpose, It was just poor planning.
The virtual file system and registry remapping were for introduced UAC, to ensure that as few programs as possible needed to “Run as Administrator”.
The “Program Files” vs. “Program Files (x86)” split was so that things like C:\Program Files\Common Files\System\ADO\msado15.dll can be installed 32-bit and 64-bit simultaneously.
The alternatives would be
1. Rename the DLL and make 32-to-64 porting difficult. (Microsoft kept
int32-bit on 64-bit windows to ease porting. Not likely.)2. Do some other kind of filesystem remapping such as
msado15.dll64(Wait until users start complaining about confusing error messages exposing what the application asks for instead of what the OS resolves it to.)3. Use fat binaries (Wait until users complain about needing to install the 32-bit version of something for one application and the 64-bit version for another when the vendor of it never made a fat-binary version.)
ssokolow (Hey, OSNews U2F/WebAuthn is broken on Firefox!),
I’m honestly not sure why ADO DLLs belong in the program files directory at all instead of the system directories that are intended for loadable DLLs. They could already support 32bit and 64bit DLL resources depending on the architecture used by a process. Fragmenting the entire program files hierarchy is something no other platform has required for 64bit migration so it’s not like MS had to do it this way.
Why should the OS use fake paths at all though? Just use the real path. It’s not confusing if it’s not fake. Microsoft were trying to outsmart 32bit applications with false paths, but the consequence is that any time those applications reported a path or let users browse the file system, the users were seeing false paths.
I’m sure I’m not the only one who saw application messages saying “xys missing”. only to check and recheck that the file was there. Especially during the transitions, most programs were still 32bit and any errors would be reported using the fake paths. That was extremely confusing and nonsensical to me before I found out what microsoft were actually doing under the hood. I imagine many other users who got caught up in the 32/64 bit program files debacle were frustrated by it as well.
Hyrum’s Law and backwards compatibility, no doubt. We’re talking about the company that made Windows 9x detect SimCity and intentionally allow use-after-free to preserve compatibility, and which bakes in a compatibility hack where NT-based versions of Windows will lie about their identity to Final Fantasy 7 to keep it from crashing.
—
Where possible, they do it as a last resort. Fragmenting Program Files was the less footgun-y solution because the only thing you’re “lying” about is where %PROGRAMFILES% is when the installer constructs the default install path. Barely any virtualization in that at all.
ssokolow (Hey, OSNews U2F/WebAuthn is broken on Firefox!),
But I do want to be very clear that a backwards compatibility problem wasn’t implied if they left the 32bit software running where it was. It would have continued to run perfectly.
The 64bit dlls could go into a new system64 directory, no virtual paths needed and no 32bit software would have gotten broken. This would have made much more sense to devs and users alike. Visual studio developers typically don’t even specify the system paths in their projects, so not only would it have been binary compatible, but it would have been source compatible too! Less work, no fake paths, less confusion, no long term baggage, etc. That would have been better all around. But…microsoft.
IMHO they shouldn’t have resorted to it at all…so what if Program Files contains some 32bit software and some 64bit software? Nobody would have cared about that. BTW I have seen 32bit binaries in Program Files and 64bit binaries in Program Files x86. It’s such an inconsistent mess, This can happen accidentally when developers use a 32bit installer with 64bit software for example. Since windows lies about the true paths, the software ends up being installed in the wrong place.
It just feels like sometimes the medicine is worse than the disease and this is one of those times.
But then it would feel like 64-bit is the also-ran and, when they finally sunset the 32-bit stuff like they did with Win16, there will be vestigial 64s everywhere.
Naming collisions in those edge cases where the same package needs to be installed in both versions.
It’s easy to be an armchair designer but reality is messy.
ssokolow (Hey, OSNews U2F/WebAuthn is broken on Firefox!),
I’m not seeing the negative. It solves all the problems. It keeps both 32bit and 64bit resources in clear sensible directories. It keeps full backward compatibility. It sets a good precedent for future architectures. ARM 32 dependencies could go into system-arm32 and system-arm64. It’s a good thing when directory names aptly describe what goes in them. But unfortunately microsoft’s solution of repurposing a directory like “system32” fails here. Furthermore it’s a major source of problems that lead us down the path of virtual path hacks and confusing errors for users.
Just think if linux did the same thing. “We’ll put 64bit shared objects in /lib32. Then we’ll create a new /liblol64 for 32bit shared objects. Then whenever 32bit processes are running, we’ll use file system trickery to make them see /liblol64 as /lib32. Users will have to remember that the directory for 32bit resources is /liblol64 so if a 32bit process reports an error message about /lib32 it’s actually referring to /liblol64 unless that application is using a special API to return the true path, in which case /lib32 is actually /lib32.” The microsoft solution is just insanely bad and I honestly don’t think it was planned.
Yes, but in hindsight I think it’s safe to say microsoft created a mess unique to windows that was technically quite avoidable. Many operating systems faced the same challenges and I dare say that all of them did it objectively better than microsoft without the complexity, confusion, redirection, and faults that microsoft invented with it’s approach.
The more one understands the problem, the uglier microsoft’s solution becomes since it just wasn’t necessary at all.
Except that’s not what Microsoft did with Program Files. They repurposed the folder that’s implicitly “Program Files for the OS’s native ISA” and created a new one named for its role as the OS’s non-native ISA… similar to how many Linux distros created /lib32 and either used /lib for 64-bit libs or symlinked it to a /lib64.
On my Kubuntu 20.04 LTS setup, which I installed fresh when I got a new SSD a year or two ago, /lib* is symlinked to /usr/lib*, /usr/lib is 64-bit libs, and /usr/lib64 contains only a ld-linux-x86-64.so.2 symlink which clearly exists for backwards compatibility.
Basically the same approach as having “Program Files” and “Program Files (x86)”, with an additional wart to work around either having moved away from the approach you propose or needing to be compatible with other distros that do it.
Program files was an unnecessary mess too though. So every time we add architectures now we have to use new virtual remapping to lie to applications about where they are running? There’s just no good reason for it, it’s complicated, results in bad messages that confuse users,, it confuses installers, it’s inconsistent. Seriously in principal there is no limit to the number of binary types windows can support simultaneously. So what about software that doesn’t fit into the two arbitrary Program Files categories? You could have Program Files (x86), Program Files (dotnet), Program Files (scripts/python/php/perl), Program Files (php), Program Files (powershell), Program Files (java), Program Files (arm32), Program Files (arm64), Program Files (davlik), Program Files (art). Technically they’re all different types of executable targets and using microsoft’s logic this means they get their own directory. It’s nonsense.
Even if you disagree, I’m quite certain the majority of users were offput by what MS has done. They have violated the keep it simple principal.
An even better approach is to keep files in the same path so they don’t have to move.from one architecture to the next. Before AMD64 windows was in a great position to do this themselves.
Program Files correlates to the /bin directory, not /libX
Program Files is a mess that doesn’t perfectly correlate to /bin or /lib. That’s why they duplicated it. They made the dumb decision to put a handful of shared dependencies in there, as I mentioned before.
CaptainN-,
You’re right, they’ve made a lot of mistakes, and those mistakes have long lasting consequences. I think it’s because they’ve rushed the process and haven’t left enough time to really fix poor designs before going public. And so the beta prototype gets approved for production.
Pretty much.
Well, every OS has bits of garbage in it so we essentially get to choose which garbage we want, unless we’re talking about temple-os of course.
It’s worth noting, in Thom’s screenshot he has examples of dot files in Windows – ALL of them are hidden by default.
Frankly this is a rather silly take. That has resulted in you dissing an elegant solution to a problem. Dot files basically hide themselves on *nix, but are easy to find if you need to find them and can be placed anywhere they are needed.
Dot files being hidden is a defacto standard, its POSIX even… if windows doesn’t hide them that isn’t anybody else’s fault. It would be trivial for MS to supporting hiding dot files. Given they how have WSL I am supprised windows 11 doesn’t have this option.
Personally I find the Appdata folder on windows to be an ugly solution. As it ALSO relies on hiding folders/files and makes the path longer for no reason. It also provides NO standard pathing for the files either….. its just a big mess of files in the exact same way except maybe they’ll be in there ore maybe they won’t AppData is dumb.
Files starting with a dot getting hidden is a bug (essentially how the “ls” command in early Unix versions hid the . and .. directories, which was by checking if a name started with a dot to save on time) promoted into a “feature”. If the user decides to have a file named to include a dot at the start of the filename, perhaps by accident, their file just disappeared. In technical terms, the problem we are having here is called “in-band communication” and it’s when control characters are transported in the same stream as the content and are also valid characters for the content. Operating systems (and standards) with more thought put into them don’t do that and store the hidden attribute in a separate stream (field). Also, devs are expected to follow the standards of the platform they are coding for (duh).
AppData is a nice way to not have app data clutter your home (with the exception of apps coded by Unix/Linux devs with a grey matter deficiency as discussed previously). It’s not as good as Android’s structure for app data where each app get its own app data directory and can’t modify the app data directories of other apps, but still better than Unix/Linux where all this stuff is dumped next to the user’s files.
AppData isn’t just a big mess – for one thing it puts all your app files into a single folder of the root directory (or allows that if apps follow the platform standard). Of course, there used to be “Application Data” and “Local Application Data” but they unified them and shortened the paths to AppData\Roaming and Appdata\Local. Junction points (Symlinks essentially) remain for compatibility.
Note the “Roaming” part though – on Windows, where roaming profiles are/were heavily used, the stuff under AppData\Roaming was meant to be ‘portable’ to other computers – an app putting data in here could trust it would be brought with it wherever the user went. Appdata\Local however was specific to this PC. If there were settings that either weren’t worth the bandwidth or time cost of moving between PCs (cache/temp files for example) or were specific to hardware, you put them in %LOCALAPPDATA%. And then there’s AppData\LocalLow, which is a special version of AppData\Local that is reserved for ‘low integrity’ app access, essentially a user level sandbox for unsafe software to run in that won’t trash your profile data.
Software is always going to create oodles of random files but AppData at least organizes it and files it away in a dedicated location for each app and each type of per-user data.
As Kurkosdr says, it may be nicer to be able to isolate further and more firmly between apps, but Windows doesn’t really have the same concept of standalone apps as Android does – applications are intended to interact with each other more on a Windows box, so the hard sandboxing of Android probably is a little too constraining on Windows.
“AppData isn’t a mess”…. proceeds to explain how Appdata is an insane crufty mess of 40 years of nonsense.
Compared to the relatively elegant single character being used to hide a file or not.
As far as putting an attribute bit in a separate field… well now every file has to have that attribute…. and you waste that much data for every small file in the system which small by today’s standards but not insignificant.
It seems rather elegant to me. Stuff you want to take with you, stuff you don’t care about, and dangerous stuff.
It was more “vs dumping it all in $HOME or %USERPROFILE%” than “vs dotfiles” anyway.
Having to change your file/foldername to hide it from tools is… very inelegant. It means you’re having to encode functional metadata into your filenames. Using a filesystem flag (like “hidden”) however – much neater, if programmers actually bother to use it.
Dotfiles are a bug made immortal through laziness.
Yeah the path length still bites me with one legacy application ( which runs 20k a seat no less). So I have to mess around with Windows soft links in some spots, where they will work.
Most OSes are designed from the bottom up. Only with newer ones, like Android/iOS, that the user experience has been the total focus. Cruft littering is an eternal battle.
While, from a Windows standpoint, the problem is nowhere near as bad as it was. Apps as a namespace/entity/block would be nice to see in OS design. Something like Debian Apt but integrated into the OS. Where strict is the norm and seamless.
ronaldst,
I really like the way the old-school approach worked whereby installing and uninstalling wasn’t much more complicated than simple directory operations. Copying an application directory was often all that was needed. No messing about with a registry, no system directories, no…just unzip the files and go. Long ago this used to be normal and it even worked for substantial applications including ms office .
We’ve been using these installers and managers as a crutch for underlying systems that are way more complicated than they need to be. I’m not against friendly management tools sitting on top, but they should be used to compliment a good underlying foundation. IMHO every platform is guilty of over-engineering the basics to the point where we need complicated tools/installers/etc just to manage them. They still leave unreferenced scraps all over the place.
Uninstalling should be akin to deleting a directory. I’d also appreciate an operating system that had strong integrity constraints just like databases do. I believe this should be a standard feature integrated into the OS. This way you can easily see and query the dependencies using only standard OS & filesystem operations without hunting down information online.
Standardizing new functionality is probably never going to happen with current desktop operating systems, there’s just too much legacy software that will never change. But it would be nice to have a fresh start and plan a better path with the benefit of hindsight that we lacked for current operating systems. In short, the world is built on “good enough” foundations, but it could be a whole lot better.
Alfman,
I agree completely. The last new desktop happening that caught my attention was ChromeOS. Sadly, we’re at been there, done that stage in desktop OSes.
Myself, I try to keep my OS tidy by installing very few stuff. I think the only binary I ever added to System32 was wget. Like Thom, my home folder is also littered with app specific folders. I won’t even go peek into AppData/ProgramData. lol
Never put any personal files into system folders. Put them somewhere else and then add that custom directory into your $PATH.
sj87,
The problem I found when I tried to developing a distro with more rational conventions was that a lot of applications are hard coded to use various system directories.
Granted these aren’t “personal files”, but sometimes they contain settings you want to change.
/usr/share/
/usr/local/
Debian pushed out new default vim settings a few years ago, including breaking terminal copy/paste, which is simply unbearable. I’ve found the easiest way to fix it is to delete the culprit out of debian vim startup scripts. It would be really nice if there was a better and standardized way to handle it across applications. Applications can be all over the place with settings and it’s not obvious at all where a particular setting is kept. Sometimes it’s in ~/ other times in /etc/ other times in /usr/.
Alfman,
That’s a nice idea.
What could be interesting also would be to put programs within the directory of each libraries they depend on so that removing said libraries would also explicitly delete the programs that depend on them.
Change the program from one lib directory to another to upgrade version.
For deduplication of the programs directory, we might need a combo of hard and soft links rather than true subdirectories.
We could think of a “two ways directory tree structure” (where any directory could have several parents instead of just one) as it might solve this dependency vs deduplication problem more elegantly and importantly more explicitly.
Parent folders : what it depends on, Subfolders : what depends on it.
I realize we tend to do the opposite (include assets and dependencies in sub folders) which makes sense for non shared objects..
Don’t know if anything of this exists, just food fo thoughts…
thomas,
Rather than folders and sub folders, I think it would be elegant to introduce the concept of foreign keys from databases into file systems. This way we can place things where they belong organizationally while still benefiting from robust constraints & dependency checks. Sort of like having a symbolic link that can be enforced and queried from both directions.
So you could see what unmet dependencies an application needs, but also which applications (if any) are using a given dependency. This would provide a nice way to find & remove unused dependencies. But for it to work software would have needed to evolve around such primitives as the common denominator. In the real world this did not happen, so even though I think it’s a good idea in principal, it may be a bridge too far to get there from where we are (ie chicken and egg problem).
I have mixed feeling about this. On Linux (or maybe it’s an Open Desktop standard by now) things have been moving towards a layout where we have .config for app configs and .local for cache and whatever random crap the apps think they need to put in my home folder. (Although there also exists third top-level directory .cache…)
I guess, in principle, it’s good to try to separate configuration files from e.g. temporary cache files and libraries, but then again this separation seems to be interpreted differently from one app to another. For example Dconf (Gnome configuration backend) stores the whole config database under .config but some other apps store their registries under .local/share. Some apps also store e.g. process locks under .config.
Does the layout matter, however?
As a user you should never need to “dot” your personal files, and you should never have the need to unhide dotted files unless you’re specifically trying to locate a system file.
What’s left is that you’re simply bothered about knowing that there are hidden files scattered around, even though it has no effect in your life.
It’s called the XDG Base Directory Specification, with XDG originally standing for “X Desktop Group” before they renamed themselves as Freedesktop.org. It’s part of the same standardization effort that produced things like the XDG Icon Naming Specification (Remember when KDE and GNOME icon themes were completely and utterly incompatible?) and the xdg-open utility.
https://specifications.freedesktop.org/basedir-spec/basedir-spec-latest.html
Basically, “Linux vs. BSD” is the wrong layer to think about whether it’s a standard, because it’s part of the standardization effort between KDE, GNOME, Xfce, etc., regardless of what OSes they do or don’t run on.
It’s because the spec communicated the purpose of the .config vs. .local/share split very badly and, even if you know, it aligns poorly with real-world concerns. (.config is meant for machine-specific/non-roaming config, .cache is meant for non-roaming cache files, and .local/share is meant for “critical user data that can roam, like Thunderbird mail folders or game saves”, but there’s nothing for “Stuff too big to roam but not regeneratable like caches… such as installed mods for games”, so anything where the classification is non-obvious gets dumped into .local/share.)
.config/.local/AppData/etc just hides the problem, instead of solving it. My .config is also full of random folders, which yes, I don’t have to see, but are still horrible to navigate.
The real issue is that there isn’t a way to link a given file to the program it was created by. I like how Haiku automatically creates the filesystem under ~/config from the installed applications. On the GNU/Linux side we have the purge options (i.e. «apt purge») and Flatpak’s putting everything under .var, but there’s always something that remains.
To be correct flatpak does have a strict layout.
~/.var/app//
This that flatpak does in fact give you what program created what configuration file because the app-id directly links to the application responsible. Flatpak does have a clean ~/.var/app directory command.
flatpak uninstall –delete-data
The problem is not the simplest. A user can be uninstalling an application only to reinstall it again because they goofed this is why “flatpak uninstall –delete-data” is not automatic. apt purge does not do home directories configuration files yes this is a problem. There is a weakness in most distribution packaging not include home directory cleaning tools.
There is also the problem here when people start using systemd-homed or any form of roaming profiles to have home directory that moves between systems so just because a configuration in a user-home not valid for the current system does not equal that is always valid to delete.
Haiku documentation
~/config/settings/ This folder contains the settings to all applications and a few configurations for the system. Some applications manage their settings in their own subfolders, others simply put their configuration file in there.
There is no Haiku rule that applications be good in the ~/config/settings directory either.
Every application in container OS of Linux do effectively solve the every config file has assigned application and it something the application developer cannot simply screw up but these are not really popular distributions.
In regards to Unix(Linux), I disagree.
Thom even described the hidden stuff as “garbage” — ie. stuff that you do not have to see regularly; stuff that — if it were a car, would be under a hood/bonnet, or under the dashboard. When you drive a car, do you want to stare into the open engine bay or trace wires, each time?
Programmers understand that there are things that do not have to be visible, all the time. And users can always “look under the hood” anytime, if they feel the need.
A favourite quote from the heydays of Usenet might apply here:
| This is Unix, we shouldn’t be saying “why would you want to do that”,
| we should be saying “sure, you can do that if you want.” 🙂
| — Steve Hayman
A lot of UNIX tools clutter up the home directory on macOS same as with Linux. Some GUI desktop apps clutter up documents folder (tho it’s much better than it used to be). This does seem like one of those things that Window might just be better.
Well, at least on Windows, I can click the “Hidden” checkbox on all the immovable trash like “Saved Games”, “SavedGames”, and other folders full of game save files that get put into My Documents and then add a “don’t copy/sync hidden files” flag to any process where I intend to only copy non-AppData personal files.
Thankfully, Flatpak on Windows and turning a hand-me-down Win7 prebuilt PC into a dedicated gaming rig has resolved the problem nicely. Sandboxing for the former, nothing but save files in My Documents for the latter.
Why can’t we have a singular binary repository database with obscure, unknown, secret settings that’s at least 100 times more complex?
As a lowly user, I fail to see the problem with dot files. I can have a tidy home directory in Linux AND I can access the system- and app-related config files when I need to.
This is hilarious. Quick test, find the single document that proves this point. I dare you!
https://specifications.freedesktop.org/basedir-spec/basedir-spec-latest.html
“$XDG_CONFIG_HOME defines the base directory relative to which user-specific configuration files should be stored. If $XDG_CONFIG_HOME is either not set or empty, a default equal to $HOME/.config should be used.”
“If you’re an operating system developer, don’t use hidden directories and files to hide stuff from the user – use clear directory names, encourage the use of human-readable file names and contents, and put them in places that make sense.”
At first I thought, how would you even DO that… Then I realized BeOS / Haiku has been doing it since 1995. 😛 Everything goes in “~/config/appname”, correct? Clearly labeled, no hidden files.
These “hidden directories” aren’t hidden from the user on *nix… They are hidden by default to reduce clutter. In most cases they are easy to find, clearly labelled, and when you do want to completely remove a program, you can simply find the right dot file/folder, and delete it.
I do like the BeOS standard, but the problem with standards is that when you have 14, and you and a new one, now you have 15…
https://xkcd.com/927/
If this is super important to anyone, I think the best way forward would be some mix of an API (not a standard) at the OS level (distro, not kernel), an open database of apps and their config locations (similar to PCGamingWiki’s ‘save file location’ and ‘config file location’ database), with something implemented against it to centralize those settings files. Something reactive can probably work in the short term to try and get some sanity. After a few different models are tried, one of them may stick enough to become prescriptive. But no new standard is going to fix this. Whining certainly isn’t going to fix it.
drcouzelis,
You and Thom both make good points. I’ve been gleaning several gripes from the conversations.
One is the fact that dot files have to be renamed to change a file’s hidden state. So on linux, it’s probably bad to use dot files to hide things because it implies the application has to hard code whether or not a file gets hidden, but it really shouldn’t be up to the application. If the user wants to change the hidden attribute, that should be possible without breaking the application. Changing the hidden attribute does break the application on linux, so I think we can make the case that it’s objectively bad.
While we’re on the topic of dot files, I hate that copying ‘*’ from a directory omits dot files because usually a file being hidden does NOT denote that the file is unimportant. Many FOSS projects tend to hide stuff in dot files and it’s always annoying to copy/move those files into a new directory only to discover it was incomplete due to dot files. This default behavior is wrong almost 100% of the time.
Also to Thom’s point, I think there’s validity in saying that operating systems are using hidden files as a crutch (both windows and linux) when things really don’t need to be hidden, they just need to be better organized so they don’t pollute the namespace. Thank you for mentioning the BeOS solution. Instead of hiding thousands of files, just move them into a subdirectory where their existence doesn’t offend anybody and they’re not polluting the home directory. It’s elegant and simple.
And for windows, the AppData structure isn’t ideal either.
https://www.thewindowsclub.com/local-localnow-roaming-folders-windows-10
You’ve got applications using them rather arbitrarily. This reason for this is that once again, the path/filename is being used to imply policy decisions that the application developer isn’t fit to decide. It’s really only the admin who can answer where the files should reside. That’s NOT the developer’s business, but windows forces developers to choose a path that decides policy. This was a bad approach. Perhaps it was necessitated by the limitation s of the OS, but a better solution is to have developers store data in one consistent well organized location. As for whether application files are local or roaming, these policies would be better left to the administrator. The application might provide a default setting, but this should not involving changing the path there the user and application expect those files to be!
Another big gripe that comes up is inconsistency, like how not all programs are in Program Files on windows. Microsoft are especially guilty of this and they need to shun their own developers over it. The other issue is that sometimes applications are installed per user. I’m not a fan of installing applications this way, but I understand why it’s done and sometimes necessary. To this extent, we need a dedicated directory for locally installed apps and it shouldn’t just get shoved into “AppData”.
We’re not even getting into the registry aspects, haha.
Please be more careful drcouzelis . BeOS and Haiku not all applications obey that rule.
https://www.haiku-os.org/docs/userguide/en/filesystem-layout.html
~/config/settings/ This folder contains the settings to all applications and a few configurations for the system. Some applications manage their settings in their own subfolders, others simply put their configuration file in there.
And the file system standard of BeOS and Haiku is not as clean cut as one would hope. Also note BeOS Haiku don’t demard configuration directory/configuration file name makes sense so you could have application named fox with configuration named hen and this be valid to BeOS and Haiku rules of course first response is that is not the case but then see ~/config/settings/profile with bash on Haiku. That right bash reads profile for it configuration under Haiku. But you also have ~/config/settings/bashrc.
Now here comes got to be kidding me moment Haiku and Beos. You start a terminal that auto starts bash the settings have to be in ~/config/settings/profile but now from a already running shell other than bash and you start bash and you want settings to appear they have to be in ~/config/settings/bashrc. Please note bash is a default application to come with Haiku these days. Yes the system wide bash settings don’t get picked up by user run bash at all.
Turns out Haiku is not better off in configuration handling than Linux. Some of the Linux distribution auto work around to some of these issue Linux package maintainers do don’t exist once you are on Haiku. Yes Linux distributions put in .profile if this is accessed by bash tell bash to open ,bashrc as well. Yes Linux bash system wide bash setting do get picked up if .profile and .bashrc are missing.
There is no clear hard and fast rule not all BeOS/Haiku application developers do good things yes bash is the simple example to show bad news here. Yes the ~/config/settings under beos/Haiku end up just as messed up as as normal linux just beos/Haiku did not/does not have the number of applications to make the problem really stand out. The issue is still there with Haiku.
Its linux that has the ~/.config/appname thing that not all application use.
One of the problems here other than some of immutable Linux distributions (that have their own set of downsides) there are really no examples of operating systems where user configuration has been managed cleanly.
Problem here is sod law applies with a minor wording change “if something can go wrong, it will” after wording change comes “If a developers of applications can place configuration/application files in the wrong place with the wrong name and make a mess of the complete system at some point they will. And at some point there will be enough developers making enough applications to make the system total mess”
To make it impossible to application todo the wrong think you start going more and more immutable and more and more sand-boxed so application cannot do the wrong thing. But there are prices to pay for this.
I’ve not commented on this, because in reading the discussion it seems mostly it comes from the perspective of solo desktop users / developers. However for both Linux and MS Windows the driver is probably not the isolated user experience, but the ability to manage ten thousand or many many more machines remotely.
We lament our user experience collectively in the millions, but we are not a driver of the debate, if you are IBM, GE or a Government you’ll have skin in the game. The rest of us in isolation have to work around what suits others.
ssokolow (Hey, OSNews U2F/WebAuthn is broken on Firefox!),
(replying here b/c wordpress sucks at threads…)
To me that’s the difference between a feature being build “on top of” a file system versus features being integrated “into” a file system. In database terms integrity constraints are considered very robust absent hardware/driver faults. It would be nice to see file systems incorporate some of these database concepts so that applications could make use of things like alternate indexes, etc.
In some of my projects I use things like inotify/fanotify to react to file system changes on the fly. Theoretically that could provide some automatic indexing this way, but it’s not robust like an ACID compliant database would be and it’s quite a bit less efficient.
I’m not sure what software you mean specifically, but I’m thinking of the apt package manager, and it too can get out of sync when apt’s internal state doesn’t reflect the file system state. It doesn’t like that!
Alternative indexes should be fairly easy to implement. However existing filesystems that only implement the POSIX standard don’t have the needed facilities. More advanced file systems like ZFS roll their own facilities instead of reusing OS primatives. This is extremely controversial, but doing so has enabled more file system innovation than was otherwise being accepted into the kernel. So it might be possible to implement “non standard” features like this, but we would need new userspace APIs too.
Maybe something like the packet filter just in time compiler could be used to enable the kernel to support sophisticated data models efficiently in kernel without hardcoding specific use cases.
https://www.kernel.org/doc/html/latest/networking/filter.html
If file system indexes and foreign keys were robust at the kernel level though (not merely a userspace cache that can get out of sync), then would that make any difference to you?
The back button was broken long ago when they invented “POST”, haha. It makes it very hard not to break the back button for many web applications.
I was thinking of things like launcher icon caches.
No, because I’m one of those people who already gives the side-eye to the status quo of hardlinks only being allowed for files, not directories. It’s about being able to build a mental map of the filesystem for the same reasons that, as a kid, classic Mac OS’s lack of a command prompt made me uncomfortable and, as a teenager, my strategy for using SQL was to keep the authoritative copy in an XML/JSON/whatever data file that I could hand-edit the raw text of and just use a read-only SQLite database as a cache and query engine.
Not at all. You just have POST responses emit the correct kind of HTTP redirect and use a GET to deliver a view of the updated state.
ssokolow (Hey, OSNews U2F/WebAuthn is broken on Firefox!),
That’s well and good, but how does having a robust FS index impede any of your use cases?
If you happen to be working on an interface that stores everything into the database on every postback or doesn’t otherwise have much page state, then it doesn’t matter much if you discard the posted data. But if large portions of the page content gets generated from the postback data itself, which isn’t uncommon, then it can quickly become complicated to restore the page state as it was without the benefit of previously posted data. Consider that devs can make very elaborate form interfaces in .net that regenerate on every single postback. This is completely automatic, but only as long as the data is POSTed. If you throw away the POST data, then the page state is lost and the UI can’t be trivially regenerated with a naked GET.
Maybe you can take a shortcut and go back to an empty form instead of the populated form the user submitted, but that probably is not what the user wants (who among us hasn’t click the ‘back’ only to see all the form state is lost). So if you need to be able to reproduce the page state while replacing POSTs with GETs to make the back button work, the server needs to do more work to save postback data for every page in case a user happens to hit the back button. Also keep in mind the user could hit the back button more than once, and the user may have multiple windows/tabs open. So completely fixing this isn’t trivial and the resource needed could be intensive. Depending on the nature of the application it can be a lot of work to save and regenerate client state which is why many websites only support going forwards.
It doesn’t… as long as one GROUP BY hierarchy is “the authoritative one” and the rest are just CREATE VIEW alternatives because, otherwise, “the authoritative one” devolves into “a flat list of entries, indexed by primary key or OID or GUID/UUID or inode or whatever else you want to call the unavoidable identifying primitive”.
It’s not my fault people are still trying to force the web to be an easy-deploy version of Win32API and vendors see money in servicing that delusion.
Thankfully, the only place I’ve ever had to put up with that was when I was applying for student loans while living in Ontario and doing distance education with an Alberta university (If you live in the same province as the university, the student loan office at the university will handle it for you)… judging by the way it uses redirects to countermand Back and the error messages you get if you manage to outflank the redirects, OSAP’s loan application UI is clearly something along the lines of a TN3270 terminal emulator with some kind of DSL for defining how to translate the block terminal form flow into HTML… that said I will give them props for being ahead of the curve on designing nice HTML templates within those constraints compared to other Canadian government websites of the period.